রেগুলার এক্সপ্রেশন অনেকটা ইউনিভার্সাল একটা টপিক। এটা কোনো প্রোগ্রামিং ল্যাংগুয়েজ স্পেসেফিক না, কিন্তু সব প্রোগ্রামিং ল্যাংগুয়েজেই সাপোর্ট করে। যদিও কিছু কিছু পার্থক্য আছে ল্যাংগুয়েজ অনুযায়ী, তবে মেইন আইডিয়া সেইম। আমি যেহেতু জাভাস্ক্রিপ্ট নিয়ে কাজ করি, তাই জাভাস্ক্রিপ্ট এ কিভাবে রেগুলার এক্সপ্রেশন ইউজ করা যাবে সেটা নিয়ে আলাদা করে অন্য কোনোদিন লিখবো।
তার আগে বলে নিই রেগুলার এক্সপ্রেশন কি আসলে? হ্যাঁ রেগুলার এক্সপ্রেশন হচ্ছে ক্যারেক্টার আর সিম্বলের সিকুয়েন্স যেটার সাহায্যে আপনি নির্দিষ্ট প্যাটার্ন এর টেক্সট বা স্ট্রিং সার্চ করতে পারবেন।
এখন টেক্সট সার্চ তো এভাবেই করা যায়, আমার এখানে রেগুলার এক্সপ্রেশন এর কি দরকার? হ্যাঁ আসলে এটাই জানার বিষয় কেন আমার রেগুলার এক্সপ্রেশন জানা দরকার। আমরা সবসময়েই যে প্লেইন টেক্সট এ ফোন নাম্বার বা কোনো অ্যাড্রেস সার্চ করবো এমন কিন্তু না ব্যাপারটা। একটা দুইটা টেক্সটের ক্ষেত্রে ঠিক আছে আমি একটা একটা করে ফোন নাম্বার বা অ্যাড্রেস প্লেইন টেক্সট এর সাহায্যে সার্চ করলাম, প্রয়োজনে রিপ্লেস করলাম। কিন্তু হাজার হাজার, লক্ষ লক্ষ ডাটার মধ্যে এটা করা সম্ভব না। কিন্তু রেগুলার একপ্রেশনের সাহায্যে সহজেই হাজার হাজার লক্ষ লক্ষ ডাটার মধ্যে থেকে জাস্ট প্যাটার্ন ডিটারমাইন করেই আপনি ফোন নাম্বার বা অ্যাড্রেস বের করে সেগুলোর উপর অ্যাকশন নিতে পারবেন।
আরেকটা ভালো উদাহরণ হতে পারে, ধরুন আপনার সাইটে আপনার একজন ইউজার ইমেইল অ্যাড্রেস দিয়ে রেজিস্ট্রেশন করলো। এখন আপনি কিভাবে বুঝবেন ইমেইল অ্যাড্রেস যেটা দেওয়া হয়েছে সেটা ভ্যালিড কি ভ্যালিড না? আপনার পক্ষে দুনিয়ার সব ইমেইল অ্যাড্রেস স্টোর করে সেগুলোর সাথে যাচাই করা সম্ভব না। কিন্তু আপনি ইমেইল অ্যাড্রেসের প্যাটার্ন জানেন। যে ইমেইল প্রথমে কিছু ক্যারেক্টার থাকবে, তারপর একটা @ চিহ্ন থাকবে, তারপর ডোমেইন নেইম, সবশেষে ডোমেইন এক্সটেনশন(.com, .org, .net etc etc…)। আপনি রেগুলার এক্সপ্রেশন ইউজ করে আপনার ইউজারের ইমেইলের প্যাটার্ন দেখে যাচাই করে নিতে পারবেন যে ইউজার ভ্যালিড ইমেইল অ্যাড্রেস দিয়েছে কিনা খুব সহজেই।
[email protected]
[email protected]
[email protected]
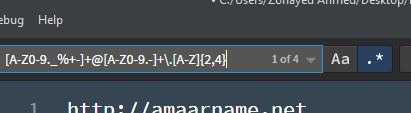
[email protected]আমি এখন এখানকার সবগুলো ইমেইল অ্যাড্রেস ম্যাচ করাতে চাইলে নিচের এই রেগুলার এক্সপ্রেশনটা লিখলেই যথেষ্টঃ
[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}আর অনেক জায়গায় Regular expression কে regex বা regexp নামেও দেখবেন। সবগুলোই রেগুলার এক্সপ্রেশন, শর্ট ফর্ম আর কি।
এই সিরিজটি আমি দুইটা পর্বে ভাগ করে লিখেছি। এটা প্রথম পর্ব, আর পরের পর্ব দেখতে চাইলে পাশে পাবেন…
প্র্যাকটিস এনভায়রনমেন্ট সেটাপঃ
আপনার পছন্দের কোড এডিটর ওপেন করে টেক্সট/কোড ফাইন্ড এর অপশন বের করলেই এর আশেপাশে রেগুলার এক্সপ্রেশন এনাবল করার বাটন পাবেন। আমি এই লেখায় অ্যাটম কোড এডিটর ইউজ করবো। এটমে ঠিক ফাইন্ড টুলবারের(Ctrl + F) ডান পাশের মাথায়ই পাবেন রেগুলার এক্সপ্রেশন এনাবল করার বাটন .* ,আর সাথের Aa বাটনটা কেস সেন্সিটিভিট করার জন্যে, আপনি যদি চান আপনার সার্চ টার্ম কেস সেন্সিটিভ হউক তাহলে এটাই এনাবল করে নিতে পারেন।
আর ব্র্যাকেটস কোড এডিটরের এখানে পাবেন .* এমন একটা বাটনঃ
আমি এখানে কেস সেন্সিটিভিটি ডিসাবল করে সব দেখিয়েছি, তাই আমাকে ফলো করতে চাইলে আপনার এটা এনাবল করার দরকার নাই।
অথবা অনলাইনে প্র্যাকটিস করতে চাইলে এখানে দেখতে পারেন। আমি এখানে ডিমো হিসেবে অনেকগুলো ডকুমেন্ট ইউজ করবো, এগুলো আপনিও আপনার কোড এডিটরে কপি পেস্ট করে প্র্যাকটিস করতে পারবেন।
মেটা ক্যারেক্টারস(Meta Characters):
রেগুলার এক্সপ্রেশনে কিছু স্পেশাল ক্যারেক্টার আছে যেগুলো বিভিন্ন কাজে ইউজ করা হয়(পরে এদের ইউসেজ আলোচনা করা হবে)। কিন্তু আপনি যদি এরকম কোনো ক্যারেক্টারকেই সার্চ করতে চান তাহলে তাদের আগে একটা স্পেশাল এসকেপ \ ক্যারেক্টার ইউজ করতে হবে। এই মেটা ক্যারেক্টার গুলো হচ্ছেঃ
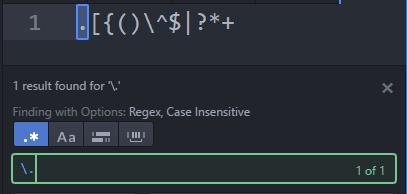
.[{()\^$|?*+ধরি আমাদের একটা .txt ডকুমেন্ট আছে যেখানে এই মেটা ক্যারেক্টারগুলো আছে:
.[{()\^$|?*+এখন ধরি আমরা ডট(.)সার্চ করতে চাচ্ছি। এখন ডটের যেহেতু রেগুলার এক্সপ্রেশনে স্পেশাল মিনিং আছে(পরে ডিসকাস করা হয়েছে), তাই আপনি সরাসরি ডট লিখে ডট সার্চ করতে পারবেন না। সেক্ষেত্রে আপনাকে এসকেপ ক্যারেক্টার \ ইউজ করতে হবে।
একই ভাবে বাকী মেটা ক্যারেক্টারগুলোর ক্ষেত্রেও প্রযোজ্য। আপনাকে এসকেপ ক্যারেক্টার ইউজ করতে হবে যদি আপনি এগুলোর মধ্যেই কাউকে স্পেসেফিকলি খুঁজতে চান।
ক্যারেক্টার ক্লাসেস(Character Classes):
এখন কিছু ক্যারেক্টার ক্লাস আছে যেগুলো স্পেশাল টাইপের ক্যারেক্টার খোঁজার জন্যে ইউজ করা হয়। এটার প্র্যাকটিস এর জন্যে আমরা এই .txt ডকুমেন্ট টা ইউজ করবোঃ
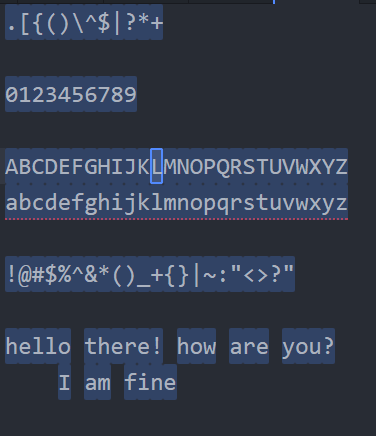
.[{()\^$|?*+
0123456789
ABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz
!@#$%^&*()_+{}|~:"<>?"
hello there! how are you?
I am fine. (ডট) => ইউজ করা হয় যেকোনো টাইপের ক্যারেক্টার খোঁজার জন্যে। যেকোনো টাইপ মানে যেকোনো টাইপ, অ্যালফাবেট, নাম্বার, স্পেশাল ক্যারেক্টার, স্পেস সবকিছু খোঁজার জন্যে। উপরে ডকুমেন্টটার জন্যে শুধুমাত্র . (ডট) লিখে সার্চ দিলে দেখবেন এই ডকুমেন্ট এর প্রত্যেকটা ক্যারেক্টারকেই এটা(একটা একটা করে) সিলেক্ট করে ফেলেছে।
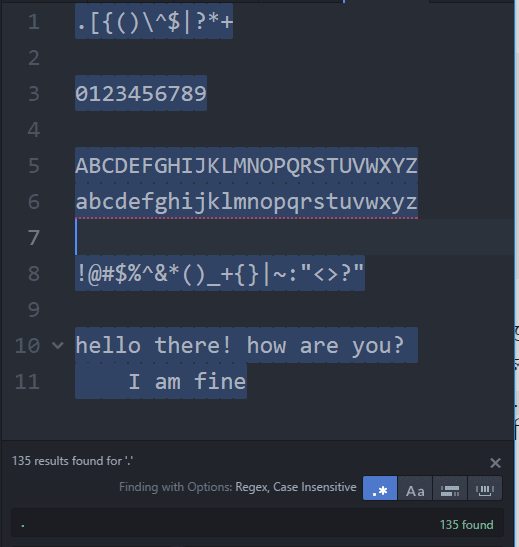
\d (ডিজিট 0–9) => এটা ডিজিট সিলেক্ট করার জন্যে ইউজ করা হয়। এটা অ্যাপ্লাই করলে দেখবেন সবগুলো ডিজিট একটা একটা করে সিলেক্ট হয়েছে

\D (ডিজিট 0–9 নয় এমন) => এটা ডিজিট নয় এমন ক্যারেক্টারগুলো সিলেক্ট করবে। ঠিক \d এর উল্টো। এখানে অ্যাপ্লাই করলে দেখবেন 0–9 পর্যন্ত ডিজিটগুলো ছাড়া বাকী সব একটা একটা করে সিলেক্ট করা হয়েছে।
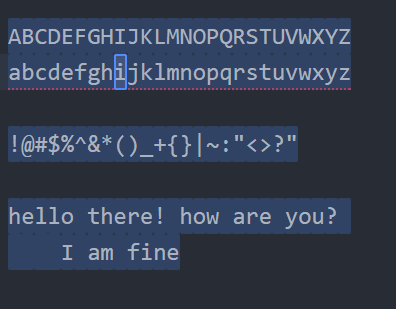
\w (ওয়ার্ড ক্যারেক্টার a-z, A-Z, 0–9, _ ) => ওয়ার্ড ক্যারেক্টার a-z, A-Z এবং 0–9 সহ _(আন্ডারস্কোর) সিলেক্ট করতে ইউজ করা হয়। অ্যাপ্লাই করলে এগুলো একটা একটা করে সিলেক্ট করবে
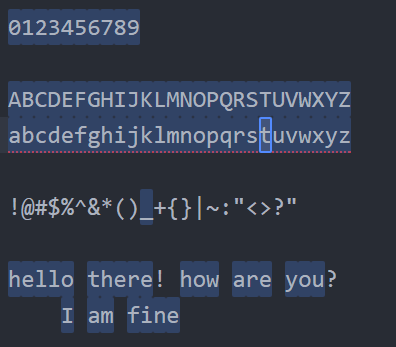
\W (ওয়ার্ড ক্যারেক্টার নয় এমন) => যেগুলো ওয়ার্ড ক্যারেক্টারের মধ্যে পড়ে না, ঐগুলো সিলেক্ট করতে ইউজ করা হয়।
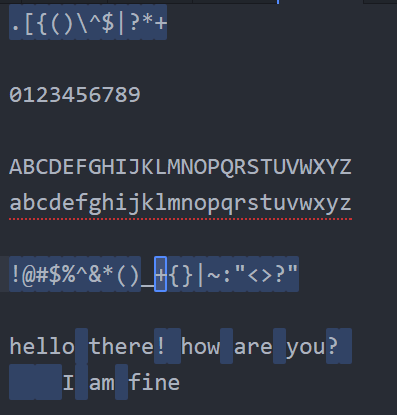
\s (স্পেস, ট্যাব বা নিউলাইন)=> যতরকমের White space আছে যেমন স্পেস, ট্যাব বা নিউলাইন সিলেক্ট করার জন্যে ইউজ করা হয়
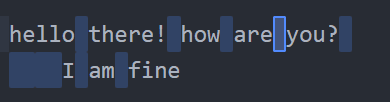
\S (স্পেস, ট্যাব বা নিউলাইন ছাড়া বাকি সব) => যেগুলো White space এর মধ্যে পড়ে না ঐধরনের ক্যারেক্টার সিলেক্ট করার জন্যে ইউজ করা হয়
***মনে রাখবেনক্যারেক্টার ক্লাসগুলো মাত্র একটা ক্যারেক্টার সিলেক্ট করে একই সাথে। পরে কিভাবে একাধিক ক্যারেক্টার সিলেক্ট করতে হবে সেগুলো দেখানো হয়েছে।
এ্যাঙ্করস (Anchors):
এ্যাঙ্করগুলো একটু অন্যরকম। এগুলো সাধারনত কন্ডিশনের মতো, যদি অমুক জিনিসটা অমুক ক্যারেক্টারের আশেপাশে, আগে বা পরে থাকে তাহলেই একমাত্র ঐ ক্যারেক্টারটা সিলেক্ট করা হবে। এ্যাঙ্কর নিজে সিলেক্ট হয় না, কিন্তু অন্য একটা ক্যারেক্টারকে সিলেক্ট করতে সাহায্য করে। এটার ডিমোর জন্যে আমরা নিচের এই টেক্সট ফাইলটা ইউজ করবোঃ
hello there! how are you?
I am fine
Hello World! How Are you? HelloJane, Hello Jake, How Are you? Hello\b (ওয়ার্ড বাউন্ডারী) => এটা যেই ক্যারেক্টারের সাথে রাখা হবে ঐ পজিশনে কোনো ওয়ার্ড বান্ডারী আছে কিনা সেটা দেখা হবে, থাকলে ঐ ক্যারেক্টারটাকে সিলেক্ট করা হবে, নাইলে সিলেক্ট করা হবে না। এখন ওয়ার্ড বাউন্ডারী কি? হ্যাঁ ওয়ার্ড বাউন্ডারী হচ্ছে এরকম কোনো ক্যারেক্টার থাকলে যেগুলো ওয়ার্ড ক্যারেক্টারের মধ্যে পড়ে না। ঐরকম কোনো ক্যারেক্টার থাকলেই সেগুলোকে ওয়ার্ড বাউন্ডারী হিসেবে ধরা হয়। এখন আমরা Hello টেক্সট টার খোঁজ করবো যেগুলোর আগে ও পরে ওয়ার্ড বাউন্ডারী আছে এভাবেঃ
\bHello\bদেখবেন এগুলো সিলেক্ট করা হয়েছেঃ
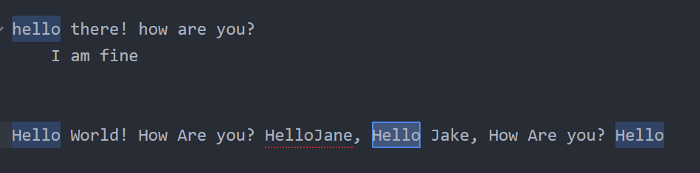
কিন্তু একটা Hello সিলেক্ট করা হয়নি? কেনো? হ্যাঁ এইটার পরে কোনো ওয়ার্ড বাউন্ডারী নাই, এটা একসাথে Jane এর সাথে লেগে আছে। তাই এটা সিলেক্ট হবেনা।
\B (ওয়ার্ড বাউন্ডারী নয়)=> ঠিক ওয়ার্ড বাউন্ডারীর উল্টো। এভাবে \bHello\B লিখে সার্চ দিলে দেখবেন এটা এখন HelloJane সিলেক্ট করেছে। কারন এটার আগে ওয়ার্ড বাউন্ডারী আছে, কিন্তু পরে নাই যেটা ম্যাচ করেছেঃ

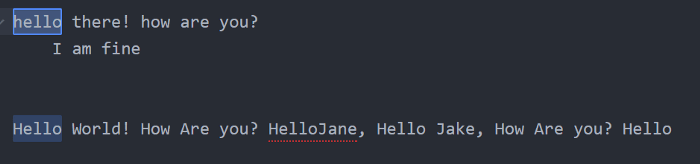
^ (লাইনের শুরুতে) => লাইনের শুরুতে আপনার কাঙ্ক্ষিত ক্যারেক্টার/স্ট্রি থাকলে সেটা সিলেক্ট করা হবে। যেমন ^Hello লিখে সার্চ দিলে শুধুমাত্র লাইনের শুরুতে থাকা Hello গুলো সিলেক্ট হবেঃ
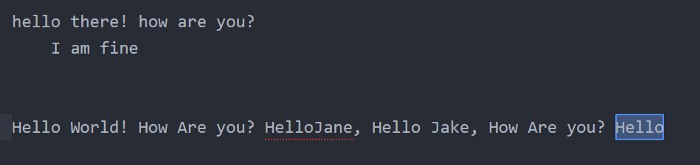
$ (লাইনের শেষে) => লাইনের শেষে আপনার কাঙ্ক্ষিত ক্যারেক্টার/স্ট্রি থাকলে সেটা সিলেক্ট করা হবে। যেমন Hello$ লিখে সার্চ দিলে শুধুমাত্র লাইনের শেষে থাকা Hello গুলো সিলেক্ট হবেঃ
\A (পুরো সার্চ এরিয়ের প্রথমে) => আপনার কাঙ্ক্ষিত ক্যারেক্টার বা স্ট্রিং পুরো সার্চ এরিয়ার একদম প্রথমে থাকলে সেটা সিলেক্ট হবে। এখানে \AHello লিখলে একদম প্রথম লাইনের প্রথম Hello টাই সিলেক্ট হবেঃ
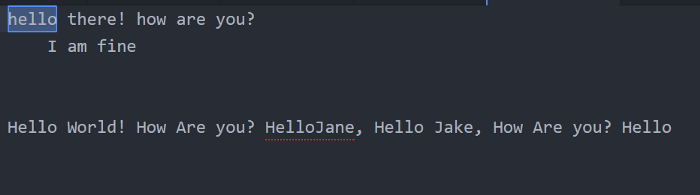
\Z (পুরো সার্চ এরিয়ের শেষে) => আপনার কাঙ্ক্ষিত ক্যারেক্টার বা স্ট্রিং পুরো সার্চ এরিয়ার একদম শেষে থাকলে সেটা সিলেক্ট হবে। এখানে Hello\Z লিখলে একদম প্রথম লাইনের প্রথম Hello টাই সিলেক্ট হবেঃ
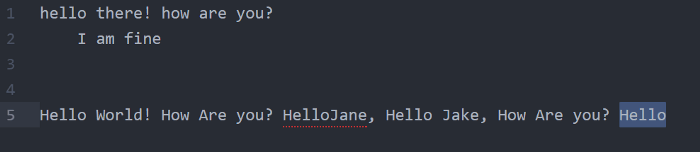
***এখানে এ্যাঙ্করগুলো ক্যারেক্টার বা স্ট্রিং এর আগে না পরে বসবে সেটা ইম্পরট্যান্ট। আগেরটা আগেই হবে, পরেরটা পরেই বসবে।
রেঞ্জ(Range)
রেঞ্জ স্পেসেফিক রেঞ্জের ক্যারেক্টার সিলেক্ট করার জন্যে ইউজ করা হয়। এইটার ডিমোর জন্যে নিচের এই টেক্সট ডকুমেন্টটা ইউজ করা হবেঃ
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyzMr Zonayed Ahmed
Mrs Ahmed Zonayed
MD Hafiz
Mr Kalim Uddin(…) (গ্রুপ) => গ্রুপিং করার জন্যে ইউজ করা হয়। সার্চ টার্মগুলো গ্রুপিং করে ঐগুলার উপরে একসাথে অন্য কোনো টার্ম অ্যাপ্লাই করতে পারবেন। আবার গ্রুপ ক্যাপচারিং এর জন্যেও গ্রুপিং ইউজ করা হয়। গ্রুপ ক্যাপচার করে পরবর্তিতে এই ক্যাপচারকৃত গ্রুপকে রেফারেন্স হিসাবে আবার ইউজ করা যায়। এ ব্যাপারে পরে বিস্তারিত আলোচনা করা হয়েছে।
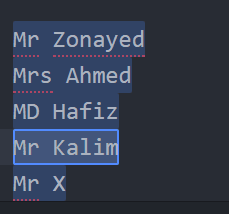
(a|b) (এটা অথবা ঐটা) => এটা অনেকটা অথবার মতো কাজ করে। আপনি এ অথবা বি থাকলে সিলেক্ট করতে চাচ্ছেন। ধরি এখানে Mr, Mrs, MD, Mr এগুলো সব সিলেক্ট করতে চাচ্ছিঃ
Mr Zonayed Ahmed
Mrs Ahmed Zonayed
MD Hafiz
Mr Kalim Uddinএখন এটার জন্যে এভাবে রেগুলার এক্সপ্রেশন সাজাতে হবেঃ
M(r|rs|D|r)
(?:…) (গ্রুপ ক্যাপচার না করা) => গ্রুপ ক্যাপচার করতে না চাইলে। পরে বিস্তারিত আলোচনা করা হয়েছে।
[abc] (রেঞ্জঃ এ অথবা বি অথবা সি) => এই [ ] ব্র্যাকেটসগুলো রেঞ্জ ডিফাইন করার জন্যে সাধারণত ইউজ করা হয়। কিন্তু এক্ষত্রে একটা একটা করে ক্যারেক্টারকে কাউন্ট করা হবে। গ্রুপের মতো স্ট্রিং বা একাধিক ক্যারেক্টার দেওয়া যাবে না। উপরের টেক্সট টায় অ্যাপ্লাই করলে Mrs ছাড়া বাকীগুলো সিলেক্ট করা যাবে এভাবেঃ
M[rDr]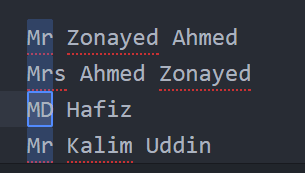
[^abc] (রেঞ্জঃ এ অথবা বি অথবা সি ছাড়া) => ^ ইউজ করে ঠিক উল্টোটা করা যায়। এখানে থাকা ক্যারেক্টারগুলো ছাড়া বাকী সব সিলেক্ট করা হবে।
M[^rDr]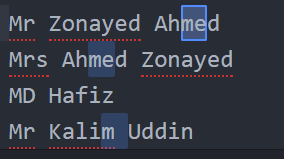
[a-z] (রেঞ্জঃ ছোটো হাতের এ থেকে জেড) => ছোটো হাতের a থেকে z এর মধ্যে কোনো ক্যারেক্টার থাকলেই সেটাকে সিলেক্ট করবেঃ
[a-z]
[A-Z] (রেঞ্জঃ বড় হাতের এ থেকে জেড) => বড় হাতের a থেকে z এর মধ্যে কোনো ক্যারেক্টার থাকলেই সেটাকে সিলেক্ট করবেঃ
[A-Z]
[0–9] (রেঞ্জঃ জিরো থেকে নাইন) => 0 থেকে 9 এর মধ্যে কোনো ডিজিট থাকলেই সেটাকে সিলেক্ট করবেঃ
[0-9]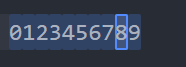
***রেঞ্জের ভিতরের মেটা ক্যারেক্টারে এসকেপ ক্যারেক্টার ইউজ করার দরকার নাই
*** ^ (ক্যারেট) এর মিনিং রেঞ্জের ভিতরে ভিন্ন
***মাল্টিপল রেঞ্জ একসাথে চাইলে একটার পর আরেকটা রেখে দিলেই হবে। এভাবেঃ [a-zA-Z0–9]
কোয়ান্টিফায়ার(Quantifier)
ইলিমেন্ট এর সংখ্যা ডিটেক্ট করার জন্যে কোয়ান্টিফায়ার ব্যবহার করা হয়। এতোক্ষন যা দেখলাম সবগুলো মোটামোটি একটা মাত্র ইলিমেন্ট সিলেক্ট করার জন্যে ইউজ করা হয়। এখন আমরা যদি মাল্টিপল ইলিমেন্ট সিলেক্ট করতে চাই তাহলেই আমাদের কোয়ান্টিফায়ার লাগবে। কোয়ান্টিফায়ার ক্যারেক্টার ক্লাস, গ্রুপ বা রেঞ্জের পরে ইউজ করা হয় ঐগুলোর সংখ্যা নির্দেশ করার জন্যে।
এখানে ডিমো হিসেবে আমরা এই টেক্সট ডকুমেন্টটা ইউজ করবোঃ
0123456789
ABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz
Mr Zonayed
Mrs Ahmed
MD Hafiz
Mr X* (শূন্যটা অথবা এরকম আরো) => এরকম রেঞ্জের, ক্যারেক্টার ক্লাসের বা গ্রুপের শূন্যটা বা এরকম আরো থাকলে সেগুলো সিলেক্ট করা হবে। এটা একটু ট্রিকি। তবে এখানে আমি যদি সবার নামে সিলেক্ট করতে চাই তাহলে এটা দিয়ে করতে পারবো এভাবে
M(r|rs|D)\s\w*প্রথমে M থাকবে, পরে r অথবা rs অথবা D থাকবে। তারপর স্পেস থাকবে, তারপর ওয়ার্ড ক্যারেক্টার থাকবে, তারপর * দিয়ে বুঝানো হলো এরকম ওয়ার্ড ক্যারেক্টার শূন্যটাও থাকতে পারে অথবা এরকম আরও থাকতে পারে।
+ (একটা অথবা এরকম আরো) => ধরি আমরা সবগুলো ডিজিট সিলেক্ট করতে চাচ্ছি একসাথে। তো আমরা রেঞ্জ [0–9] ইউজ করতে পারি। কিন্তু এক্ষেত্রে একটা একটা করে সবগুলো ডিজিট সিলেক্ট হবে, পুরোটা একসাথে হবে না। পুরোটা একসাথে করতে চাইলে ঐ রেঞ্জের শেষে + ইউজ করা যেতে পারে। এর মানে হচ্ছে এইরকম রেঞ্জের একটা বা আরো এরকম ইলিমেন্ট আছে এমন স্ট্রিং সিলেক্ট করা হবে।
[0-9]+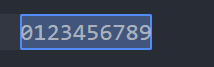
? (শূন্যটা বা একটা) => হয়তো একটা আছে নয়তো একেবারেই নাই এরকম কোনো সেট থাকলে সেটাকে সিলেক্ট করা হবে। ধরি আমি Ahmed সিলেক্ট করতে চাচ্ছি। এখন অনেকে এটাকে Ahmmed হিসেবেও লিখে। এখন এটাও যাতে আমি সিলেক্ট করতে পারি সেজন্যে এরকমভাবে লিখতে পারিঃ
Ahmm?ed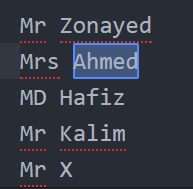
{3} (ঠিক এতোটা, এখানে তিনটা) => যদি আমরা একই রকমের কোনো ক্যারেক্টার বা প্যাটার্ন নির্দিষ্ট নাম্বারে খোঁজ করতে চাই তাহলে এটা ইউজ করা যেতে পারে। এখানে ভালো উদাহরণ হিসাবে যায় যদি আমরা সব ডিজিট খুঁজতে চাই। আমাদের এখানে টোটাল ডিজিট আছে দশটা। ধরি আমরা পাঁচটা পাঁচটা করে খুঁজতে চাইঃ
\d{5}
{3,} (এতোটা বা তারচেয়ে বেশী, এখানে তিনটা বা তারচেয়ে বেশী) => এটাও আগেরটার মতো। এতোটা বা তার বেশী থাকলে সেগুলো সিলেক্ট করা হবে। ধরি আমরা ওয়ার্ড ক্যারেক্টারগুলো ২০ টার বেশী থাকলে সেগুলো সিলেক্ট করতে চাইঃ
\w{20,}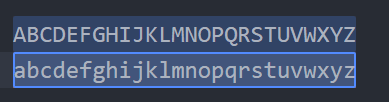
{3,5} (মিনিমান, ম্যাস্কিমাম। এখানে মিনিমাম তিনটা বা ম্যাক্সিমাম পাঁচটা) => এটাও ঠিক আগেরগুলোর মতো, কিন্তু এক্ষেত্রে মিনিমাম বা ম্যাস্কিমাম রেঞ্জ ডিফাইন করে দেওয়া হয়েছে।
***এই ( * + {}) কোয়ান্টিফায়ারগুলোকে গ্রিডি(Greedy)অপারেটর বলা হয়, এদের ইউজ করা হলে এরা যতটুকু পর্যন্ত সম্ভব পুরোটা সিলেক্ট করে ফেলে। আপনি এই গ্রিডি অপারেটরগুলোকে চাইলে লেজি(Lazy) করতে পারবেন এগুলোর শেষে ? অপারেটর ইউজ করে।
***যেমন, গ্রিডি h.+l 'hell' ম্যাচ করবে'hello' থেকে কিন্তু লেজি h.+?l শুধুমাত্র'hel' ম্যাচ করবে।
প্যাটার্ন মডিফায়ার(Pattern Modifiers):
রেগুলার এক্সপ্রেশনগুলো সাধারনত বিভিন্ন জায়গায় এভাবে দুইটা \regex\ এর ভিতরে ইউজ করা হয়। এটার শেষের দিকে এই প্যাটার্ন মডিফায়ারগুলো ইউজ করে আপনি আপনার পুরো এক্সপ্রেশন কিভাবে কাজ করবে সেটা বলে দিতে পারবেন। যদিও এটা আমাদের অ্যাটম কোড এডিটরে বা ব্র্যাকেটস এ কাজ করবে না, কিন্তু জেনে রাখা ভালো। প্যাটার্ন মডিফায়ার গুলো সাধারনত এভাবে বসেঃ
\regex\pattern_modifierকেস ইন্সেন্সিটিভ করতে চাইলে পুরো এক্সপ্রেশনটাকেঃ
\regex\iএরকম আরো কিছু প্যাটার্ন মডিফায়ারঃ
g => Global Match
i => Case-insensitive
m => Multiple lines
s => Treat String as Single line
x => Allow Comments and white space in pattern
e => Evaluate replacement
U => Lazy pattern
প্রথম ব্যাসিকগুলো অনেকটাই ক্লিয়ার করা চেষ্টা করেছি। দ্বিতীয় পর্বে আরো কিছু অ্যাডভান্স টপিকসহ কিছু রিয়েল লাইফ উদাহরণ নিয়ে আসবো। দ্বিতীয় পর্ব দেখতে চাইলে এখানে পাবেনঃ
সাবস্ক্রিপশন সেন্টার
তখনই তা আপনার ইমেইলে পেতে সাবস্ক্রাইব করুন। নো স্প্যামিং প্রমিজ!